

What are Large Language Models (LLMs)?
At their heart, Large Language Models (LLMs) are a class of sophisticated AI models designed to understand, generate, and interact with human language. These powerful models are trained on colossal amounts of text data, enabling them to learn intricate patterns, grammar, semantics, and even a vast amount of factual knowledge. Their capabilities span a wide array of tasks, including answering questions, summarizing documents, translating languages, writing creative content, and even generating code.
The transformative impact of LLMs is evident across numerous industries, from enhancing customer service with intelligent chatbots to accelerating research and development. However, to truly harness their potential and overcome challenges like poor LLM response quality or LLM output inconsistency, a fundamental understanding of their underlying architecture is crucial. This foundational knowledge empowers users to craft effective LLM prompts and developers to optimize LLM performance.
For a broader academic introduction to these models, refer to this Comprehensive Overview of Large Language Models.
The Heart of Modern LLMs: Understanding the Transformer Architecture
The vast majority of modern Large Language Models, including groundbreaking models like GPT-3, BERT, and LLaMA, owe their existence and impressive capabilities to a single, revolutionary invention: the Transformer architecture.
Introduced in the seminal 2017 paper "Attention Is All You Need" by Vaswani et al. [1], the Transformer fundamentally changed how we approach natural language processing (NLP). As the authors famously stated, "We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train" [1].
This architecture is a key component of LLMs, as highlighted by sources like SaM Solutions [2] and Tiya Vaj [3], enabling sophisticated context understanding and efficient processing of language.
For a detailed academic perspective on Transformers, the CMU Lecture: Transformers and Large Language Models provides excellent insights.
Beyond Recurrence: Why Transformers Revolutionized NLP
Before the Transformer, recurrent neural networks (RNNs) and their more advanced variants, Long Short-Term Memory (LSTMs), were the state-of-the-art for sequence processing. While effective, RNNs processed information sequentially, meaning each word in a sentence had to be processed one after another. This sequential nature made them slow, difficult to parallelize, and prone to forgetting information over long sequences—a problem known as the "long-range dependency" issue.
The Transformer architecture, by contrast, introduced parallel processing of input sequences, allowing it to handle long-range dependencies far more effectively. This marked a significant leap forward in NLP, accelerating training times and improving model performance across a wide range of tasks.
This historical context of language models, from n-grams to RNNs and LSTMs, is crucial for appreciating the Transformer's impact, as explored in surveys like "History and Principles of Large Language Models" [5].
The Encoder-Decoder Stack: Processing Input and Generating Output
The Transformer architecture is typically composed of two main parts: an Encoder and a Decoder, each consisting of multiple identical layers stacked on top of each other.
- Encoder: The encoder's role is to process the input sequence (e.g., your prompt) and transform it into a rich, contextualized numerical representation (a set of vectors). Each layer in the encoder stack contains a multi-head self-attention mechanism and a position-wise feed-forward neural network.
- Decoder: The decoder's role is to take the encoder's output and generate the desired output sequence (e.g., the LLM's response) one token at a time. Each decoder layer also includes a multi-head self-attention mechanism (masked to prevent attending to future tokens), a multi-head cross-attention mechanism (which attends to the encoder's output), and a position-wise feed-forward network. This auto-regressive generation means each new word is predicted based on the input and all previously generated words.
The Magic of Attention: How LLMs Focus and Understand Context
The true innovation and "magic" behind the Transformer, and thus modern LLMs, lies in the attention mechanism, particularly self-attention. Unlike previous models that struggled with understanding how words relate to each other across long distances in a sentence, attention allows the model to weigh the importance of different words in an input sequence relative to each other.
At a simplified mathematical intuition, self-attention works by calculating three vectors for each word in the input: a Query (Q), a Key (K), and a Value (V).
- Query (Q): Represents what the current word is looking for.
- Key (K): Represents what the other words can offer.
- Value (V): Contains the actual information of the other words.
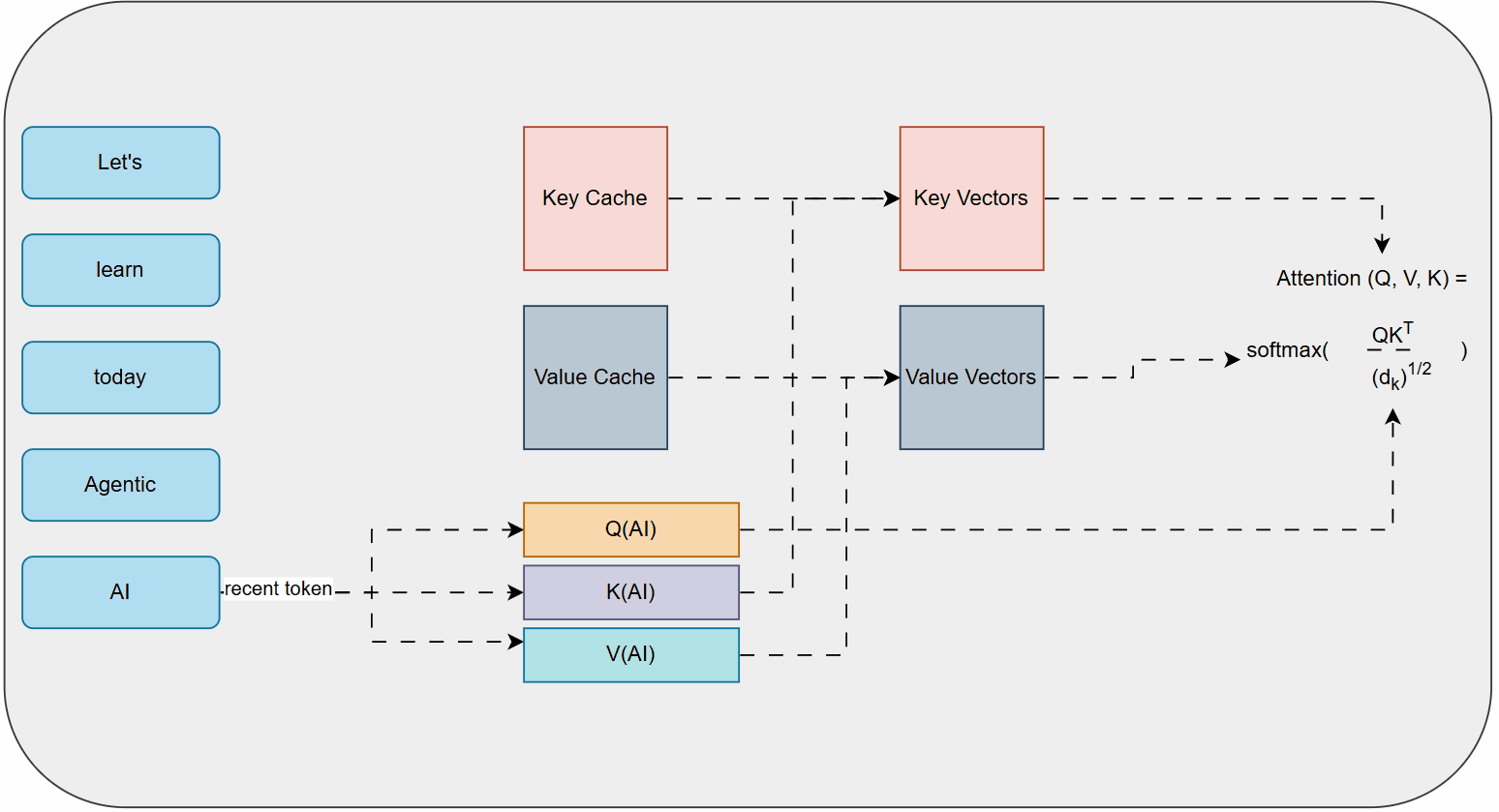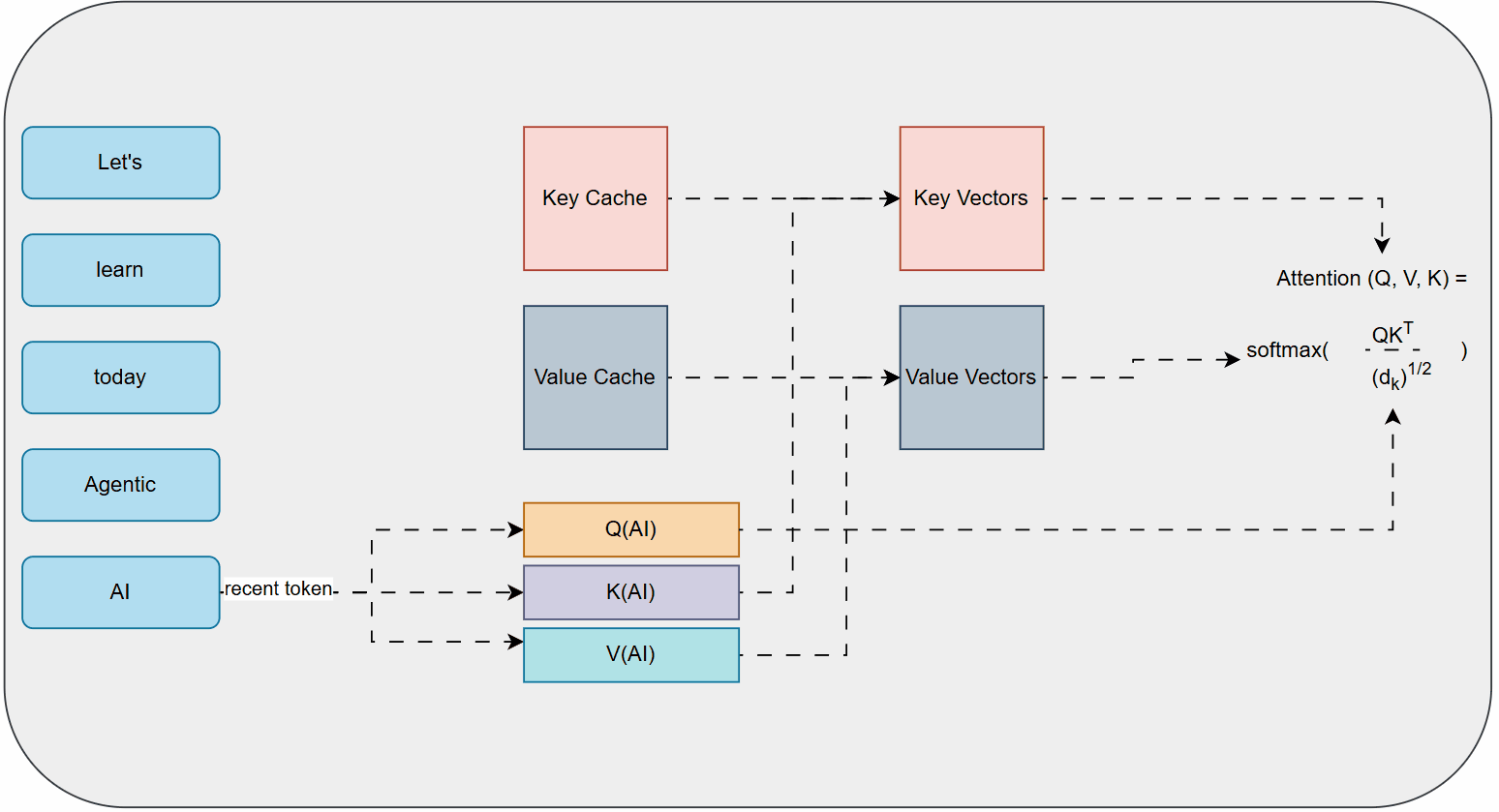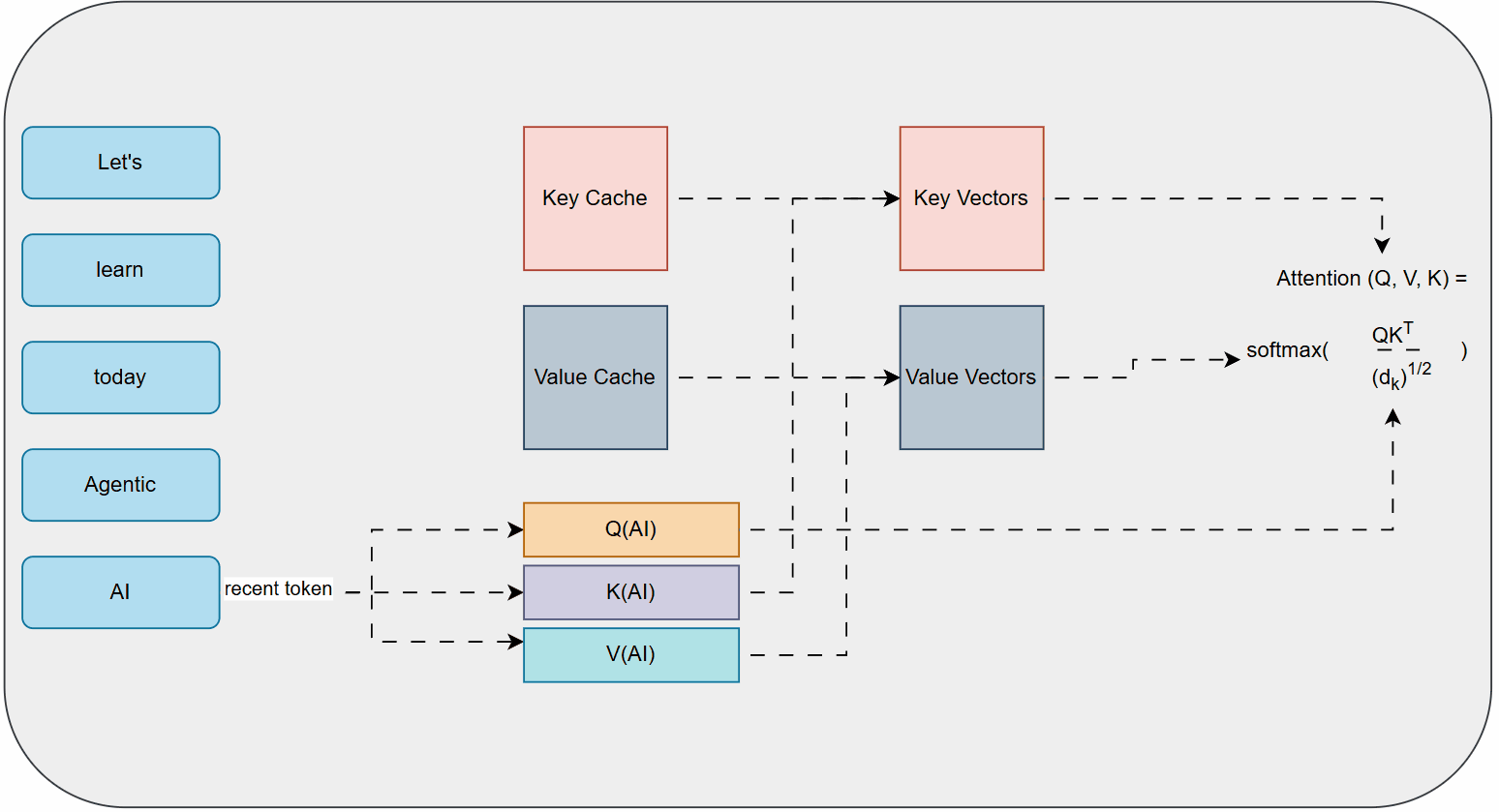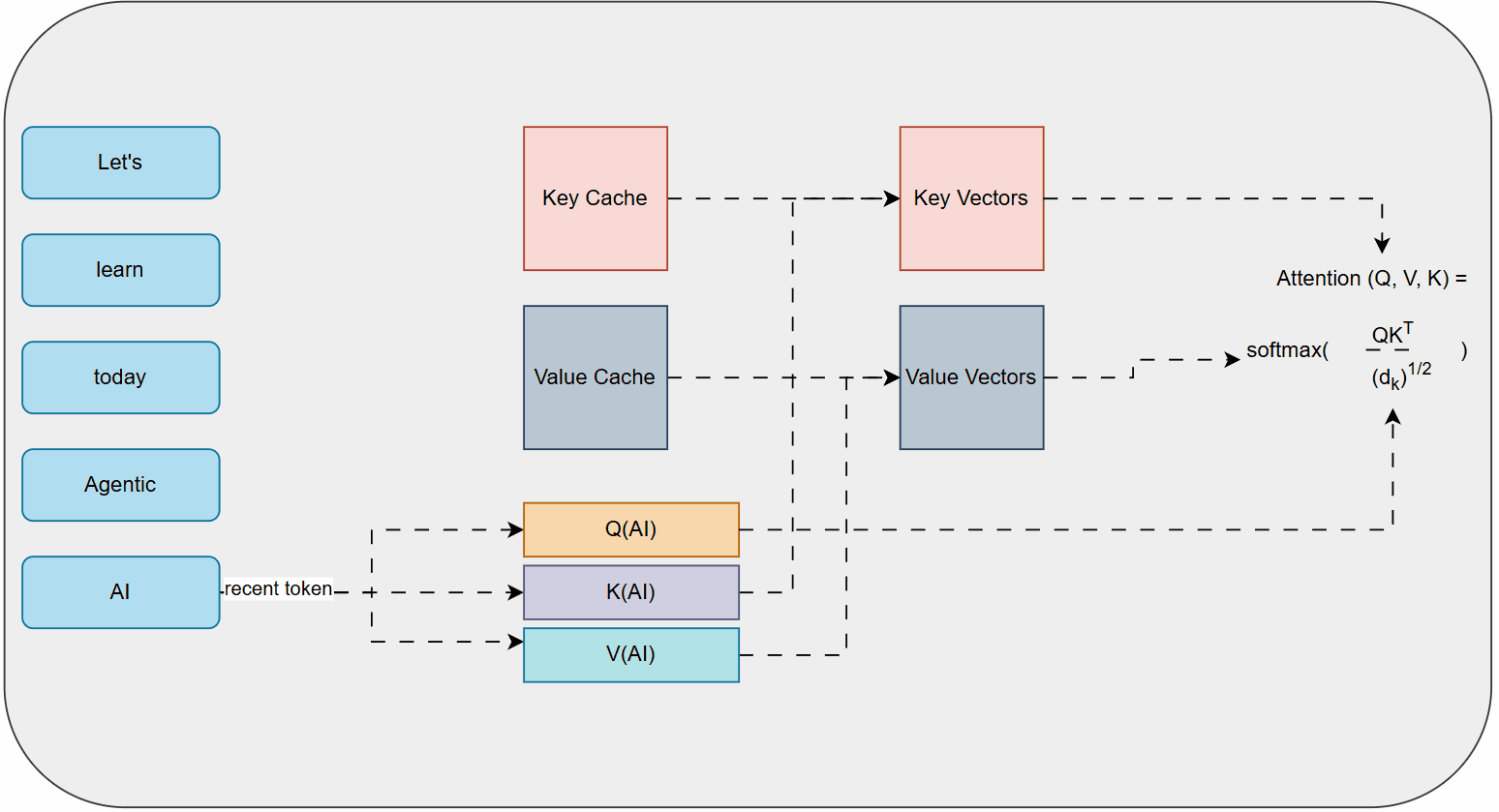
To determine how much attention a word should pay to other words, the model computes a score by taking the dot product of the Query of the current word with the Keys of all other words. These scores are then scaled and passed through a softmax function to get attention weights, which are then multiplied by the Value vectors and summed up. This process effectively allows each word to "look at" and "attend to" all other words in the sequence, creating a rich contextual representation.
Multi-Head Attention: Capturing Diverse Relationships
To further enrich its understanding, the Transformer employs Multi-Head Attention. Instead of performing one attention calculation, it performs several in parallel, each with different learned Q, K, and V weight matrices. Each "head" can learn to focus on different aspects of the relationships between words. For instance, one head might prioritize syntactic relationships (e.g., subject-verb agreement), while another might focus on semantic relationships (e.g., synonyms or related concepts). The outputs from these multiple heads are then concatenated and linearly transformed, allowing the model to capture diverse relationships simultaneously, significantly enhancing LLM understanding.
Positional Encoding: Giving Words a Sense of Order
A unique challenge for Transformers, due to their parallel processing nature, is that they inherently lose information about the order of words in a sequence. This is where Positional Encoding comes in. Before words are fed into the encoder or decoder, a vector containing information about the word's position in the sequence is added to its embedding. This allows the model to understand the relative or absolute position of each token, which is crucial for maintaining grammatical structure, logical coherence, and overall meaning. Common methods involve using sinusoidal functions of different frequencies, providing a unique positional signal for each position.
The LLM Lifecycle: From Training to Intelligent Generation
Understanding the LLM architecture is only one part of the equation; comprehending its complete lifecycle—from initial training to fine-tuning and inference—reveals how these models learn and produce their remarkable outputs. This lifecycle involves immense computational resources, a practical understanding of which is vital for aspiring engineers.
Pre-training: The Foundation of General Knowledge
The journey of an LLM begins with pre-training, an unsupervised learning phase where the model is exposed to truly massive datasets of text and code. As identified in our research, LLMs are trained on hundreds of billions of words [4]. This enormous scale and diversity of data are critical, enabling the model to learn general language patterns, grammar rules, factual knowledge, common sense, and various writing styles without explicit human labels.
During pre-training, LLMs typically learn through objectives like:
- Masked Language Modeling (MLM): The model predicts masked-out words in a sentence (e.g., "The cat sat on the
[MASK]"). - Next-Token Prediction: The model predicts the next word in a sequence given the preceding words (e.g., "The quick brown fox
[JUMPS]").
This phase builds the foundational "general knowledge" of the LLM, making it a powerful general-purpose language understanding and generation tool.
Fine-tuning: Adapting LLMs for Specific Tasks
While pre-training provides a broad understanding of language, it doesn't necessarily make an LLM proficient at specific, nuanced tasks. This is where fine-tuning comes in. In this supervised learning phase, a pre-trained LLM is further trained on smaller, task-specific datasets with labeled examples. The goal is to adapt the model's knowledge and behavior for particular applications, thereby optimizing LLM performance.
Practical examples of fine-tuning include:
- Sentiment Analysis: Training an LLM on a dataset of movie reviews labeled as positive, negative, or neutral.
- Summarization: Fine-tuning on pairs of long documents and their concise summaries.
- Question Answering: Training on datasets of questions and their corresponding answers from specific texts.
Modern fine-tuning often involves techniques like instruction tuning, where the model is trained on a diverse set of tasks described in natural language instructions, making it better at following user commands. Additionally, Parameter-Efficient Fine-Tuning (PEFT) techniques, such as Low-Rank Adaptation (LoRA), have emerged to reduce the computational cost and memory footprint of fine-tuning by only updating a small subset of the model's parameters.
For deeper insights into instruction tuning, the Stanford: Post-training and Instruction Tuning for LLMs is an excellent resource.
Inference: Generating Human-like Text
The final stage of the LLM lifecycle is inference, where the trained and potentially fine-tuned LLM processes new input (your prompts) and generates coherent, contextually relevant text.
The process typically involves the LLM generating text token-by-token (a token can be a word, part of a word, or punctuation). For each new token, the model predicts the probability distribution over its entire vocabulary. Decoding strategies then come into play to select the next token:
- Greedy Search: Always picks the token with the highest probability. This can lead to repetitive or suboptimal text.
- Beam Search: Explores multiple high-probability paths simultaneously, often leading to more coherent and high-quality output, though it's computationally more expensive.
- Top-K Sampling: Randomly samples the next token from the k most probable tokens.
- Top-P (Nucleus) Sampling: Randomly samples from the smallest set of tokens whose cumulative probability exceeds a threshold p.
These decoding strategies influence the creativity, diversity, and quality of the LLM output, allowing for a balance between coherence and novelty when generating human-like text.
The Power of Data: Fueling LLM Performance and Capabilities
The sheer scale and quality of data are paramount to the success of Large Language Models. As previously noted, LLMs are trained on massive amounts of text data, often hundreds of billions of words.
However, it's not just about quantity; data quality is equally critical. High-quality, diverse, and clean datasets minimize bias, improve factual accuracy, and enhance the model's ability to generalize across various tasks. Conversely, biased or low-quality training data can lead to LLM output inconsistency, factual inaccuracies, and perpetuate harmful stereotypes.
The ability to effectively manage and leverage these vast datasets is a significant challenge. AI-ready data platforms play a crucial role in preparing, processing, and serving data to LLMs, particularly for real-time analytics and applications. As KX highlights, such platforms are essential for fully leveraging LLM architecture for optimal performance [4]. The ongoing curation, filtering, and ethical considerations surrounding training data remain active areas of research and development.
Evolution and Future: Beyond the Transformer Horizon
While the Transformer architecture has dominated the LLM landscape for years, the field of AI is characterized by relentless innovation. Understanding the historical context of LLM development and looking at emerging trends is crucial for staying ahead.
A Brief History of Language Models (Pre-Transformer)
Before the Transformer, language models evolved through several stages. Early models included simple n-gram models that predicted the next word based on a fixed window of preceding words. The advent of neural networks brought Recurrent Neural Networks (RNNs) and their successors, Long Short-Term Memory (LSTMs), which could process sequences and maintain a form of "memory." While groundbreaking for their time, these models were limited by their sequential processing and difficulty in capturing very long-range dependencies, setting the stage for the Transformer's revolution [5].
Emerging Architectures: Beyond Pure Transformers
While Transformers remain foundational, researchers are actively exploring alternative architectures to address their known limitations, such as high computational cost for very long sequences and quadratic scaling of attention.
One prominent example of an emerging architectural paradigm is State-Space Models (SSMs), with Mamba being a notable recent development. Mamba aims to achieve the performance of Transformers while offering linear scaling with sequence length, making it potentially more efficient for extremely long contexts.
Comparative Analysis: Mamba vs. Transformer
- Transformer: Relies on global self-attention, allowing it to weigh all input tokens against each other. This is powerful for capturing complex relationships but computationally intensive (quadratic complexity with sequence length). It excels in tasks requiring broad contextual understanding.
- Mamba: Uses a selective state-space model that processes sequences efficiently by maintaining a compressed "state." It selectively propagates information through this state, achieving linear complexity. This can lead to faster inference and training for long sequences, making it a strong contender for applications where efficiency and speed are paramount, or where very long context windows are needed.
While Mamba shows promise for efficiency, Transformers still hold advantages in certain areas due to their explicit global attention mechanism. The future likely involves hybrid LLMs that combine the strengths of both, or entirely new architectures that learn from these advancements.
Multimodal LLMs: Bridging Text, Images, and More
A significant trend in LLM evolution is the expansion into multimodal LLMs. These models are designed to process and generate content across different data types, not just text. They can understand and integrate information from images, audio, video, and other modalities. This capability opens up vast new application possibilities, such as:
- Generating captions for images.
- Answering questions about visual content.
- Creating videos from text descriptions.
- Transcribing and summarizing audio.
Multimodal LLMs represent a leap towards more comprehensive generative AI, mimicking human perception and understanding more closely.
Challenges and Ethical Considerations in LLM Architecture
Despite their advancements, LLMs and their underlying architectures face ongoing challenges:
- Interpretability: Understanding why an LLM makes a particular decision or generates a specific output remains difficult, posing a "black box" problem.
- Energy Consumption: Training and running large models require enormous computational resources and energy, raising environmental concerns.
- Bias Mitigation: LLMs can inherit and amplify biases present in their training data, leading to unfair or discriminatory outputs. Developing architectures and training methods that actively mitigate bias is crucial.
- Ethical Implications: The widespread use of powerful AI models raises profound ethical questions regarding misinformation, job displacement, and the nature of human-AI interaction.
Addressing these challenges requires continued research into more efficient architectures, robust data curation, and thoughtful ethical frameworks.
Conclusion
Our journey "Beyond the Hype" has taken us deep into the fascinating world of Large Language Models. We've demystified the foundational Transformer architecture, understanding how its attention mechanisms allow LLMs to process information in parallel and grasp complex contextual relationships. We traced the LLM lifecycle from massive pre-training, where models acquire general knowledge from hundreds of billions of words, to fine-tuning for specific tasks, and finally to the intelligent generation of human-like text through sophisticated decoding strategies.
For curious minds and aspiring engineers, understanding these intricate details transforms LLMs from "black boxes" into powerful, comprehensible tools. The field of AI is rapidly evolving, and your continuous learning and experimentation are key.
Embark on your own journey: Start experimenting with LLMs, explore emerging architectures, and contribute to the future of AI. Share your insights and continue learning!
Ready to Go Beyond the Model?
You've successfully delved deep into the Transformer architecture and the complex lifecycle of Large Language Models (LLMs). Understanding Attention, Positional Encoding, and Fine-tuning is the critical first step.
Now, it's time to stop just analyzing LLMs and start building with them.
If you are eager to leverage this architectural knowledge to create sophisticated, autonomous technologies, enroll in the AI Agent Mastercamp by Capabl to learn how to design and deploy intelligent Agentic AI systems. Alternatively, if your focus is on implementing powerful AI solutions without coding, the AI LeadCamp will equip you with the essential no-code strategies.
Transform your understanding into real-world impact. Build the future with Capabl!
🔗 Discover the Agentic AI Mastercamp & Agentic AI LeadCamp
References
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. arXiv. Retrieved from https://arxiv.org/abs/1706.03762
- SaM Solutions. (N.D.). LLM Architecture: Understanding the Core Components. Retrieved from https://sam-solutions.com/blog/llm-architecture/
- Vaj, T. (N.D.). Key Components of LLMs. Medium. Retrieved from https://vtiya.medium.com/key-components-of-llms-484b4c145a1b
- KX. (N.D.). LLM Architecture. Retrieved from https://kx.com/glossary/llm-architecture/
- Shao, M., Basit, A., Karri, R., & Shafique, M. (2024). History, Development, and Principles of Large Language Models—An Introductory Survey. arXiv. Retrieved from https://arxiv.org/html/2402.06853v1
Inspire Others – Share Now
Agentic AI Saksham
India’s Only 1st Ever Offline Hands-on program that adds 4 Global Certificates while making you a real engineer who has built their own AI Agents
EV
Saksham
India’s Only 1st Ever Offline Hands-on program that adds 4 Global Certificates while making you a real engineer who has built their own vehicle
Agentic AI LeadCamp
From AI User to AI Agent Builder — Capabl empowers non-coding professionals to ride the AI wave in just 4 days.
Agentic AI MasterCamp
A complete deployment ready program for Developers, Freelancers & Product Managers to be Agentic AI professionals

.png)
Table of Contents
1) What are Large Language Models (LLMs)?
2) The Heart of Modern LLMs: Understanding the Transformer Architecture
3) Beyond Recurrence: Why Transformers Revolutionized NLP
4) The Encoder-Decoder Stack: Processing Input and Generating Output
5) The Magic of Attention: How LLMs Focus and Understand Context
6) Multi-Head Attention: Capturing Diverse Relationships
7) Positional Encoding: Giving Words a Sense of Order
8) The LLM Lifecycle: From Training to Intelligent Generation
9) Pre-training: The Foundation of General Knowledge
10) Fine-tuning: Adapting LLMs for Specific Tasks
11) Inference: Generating Human-like Text
12) The Power of Data: Fueling LLM Performance and Capabilities
13) Evolution and Future: Beyond the Transformer Horizon
14) A Brief History of Language Models (Pre-Transformer)
15) Emerging Architectures: Beyond Pure Transformers
16) Multimodal LLMs: Bridging Text, Images, and More
17) Challenges and Ethical Considerations in LLM Architecture
18) Conclusion



