

Introduction
It's been an interesting year for AI-assisted coding, and one of the most significant architectural shifts came with GitHub's launch of a brand-new embedding model for VS Code in 2025. This wasn't just a minor update; it represented a fundamental leap in how Copilot understands and interacts with code. The core mission was to dramatically improve Copilot’s context-awareness and code retrieval capabilities, especially for developers navigating large, complex projects.
This new model fundamentally replaces traditional keyword search with semantic, vector-based matching. Instead of relying on exact word or token overlaps, the model computes the meaning of code snippets and queries, enabling highly relevant retrieval even with completely different syntax. This semantic understanding is precisely what makes the new system designed to help Copilot work effectively in massive, sprawling codebases, moving beyond the constraints of simply looking at the currently open file.
What’s New in the Copilot Embedding Model?
The immediate impact of the 2025 model release is best captured by the raw performance metrics. Developers are seeing a 37.6% retrieval quality improvement and a remarkable 2× throughput increase over the previous generation models. This isn't just a win for the model itself; it translates directly to lower latency and more accurate suggestions for users in their daily coding routines.
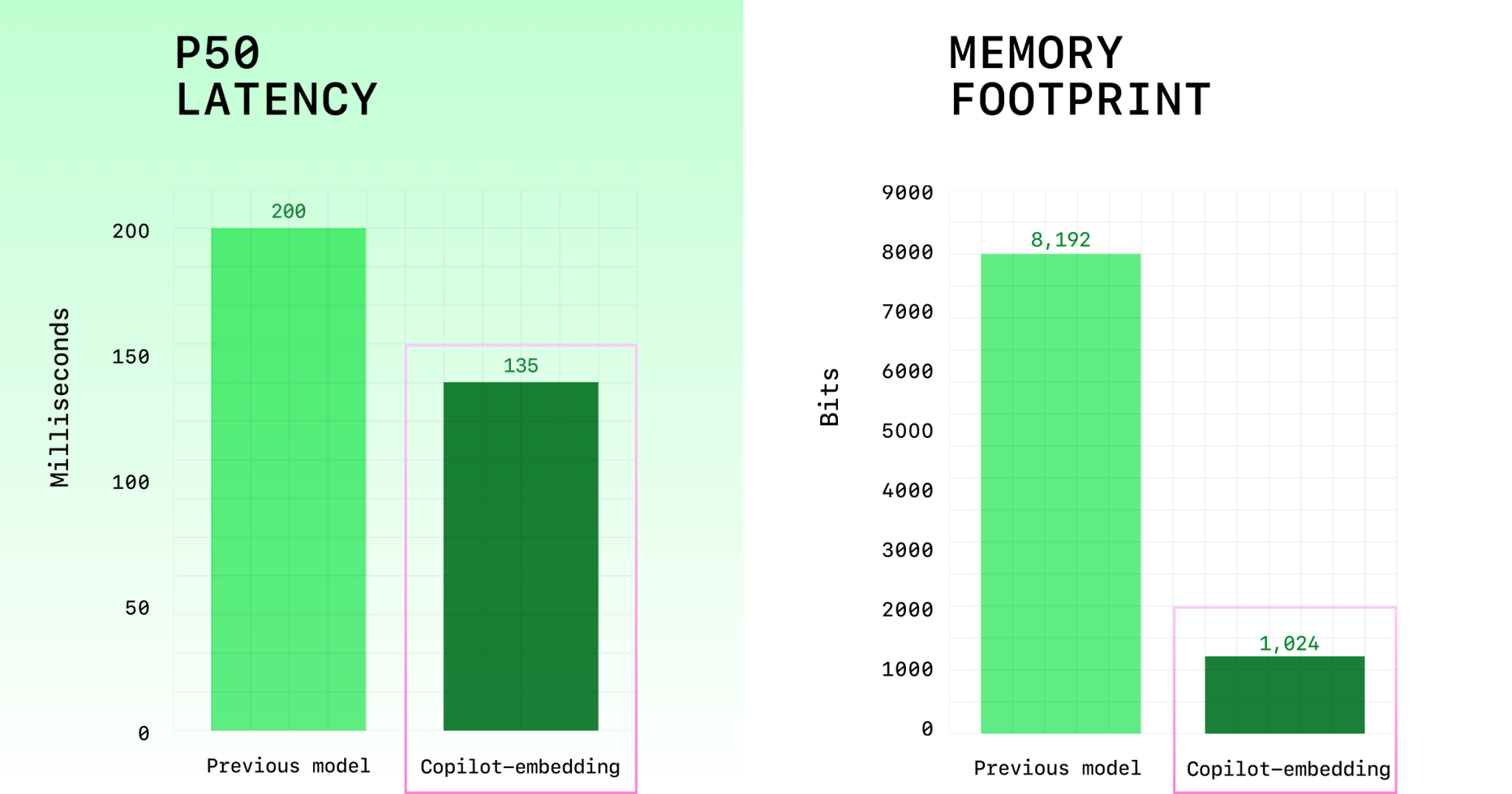
Furthermore, the engineering teams have made massive strides in efficiency, successfully reducing the memory index by 8× for exceptional scalability. This means the model can index and efficiently search much larger repositories, opening up new possibilities for enterprise-level adoption. The real-world impact is already tangible, with the model’s acceptance rates in critical languages like C# and Java having doubled, a clear sign that the improved context is driving better, more usable suggestions. The model has also been designed to support all Copilot modes, Chat, Agent, Edit, and Ask, providing a unified, high-quality experience. Finally, its seamless VS Code integration ensures the speed and interactivity that developers demand from a modern, AI-powered tool.
Under the Hood: Technical Improvements
The architectural improvements driving this performance leap are rooted in sophisticated training methodologies. At its core, the model utilizes contrastive learning and the InfoNCE loss function to effectively differentiate between semantically similar and dissimilar code snippets. This rigorous training forces the model to learn a highly discriminative latent space where relevant code is tightly clustered, while irrelevant code is pushed far apart.
A standout technical innovation is the implementation of Matryoshka Representation Learning (MRL). This technique allows the model to produce multi-granularity embeddings, ranging from small code methods all the way up to full files. MRL ensures that Copilot can retrieve context at the most appropriate level of detail, whether it needs a single function signature or the context of an entire module. To further increase the model’s robustness, the training incorporated the extensive use of hard negatives, code snippets that are superficially similar but contextually irrelevant, making the final retrieval process far more resilient and accurate in diverse coding environments. The model was trained extensively on a vast corpus of code from GitHub and Microsoft’s internal repositories, covering essential languages such as Python, Java, C++, JavaScript/TypeScript, and C#.
Performance & Benchmark Results
The new model has demonstrated clear, quantifiable superiority across internal and external benchmarks. The headline figure is the average retrieval score, which rose from 0.362 to an impressive 0.498 on internal relevance metrics. This substantial gain directly reflects the 37.6% retrieval quality improvement reported.
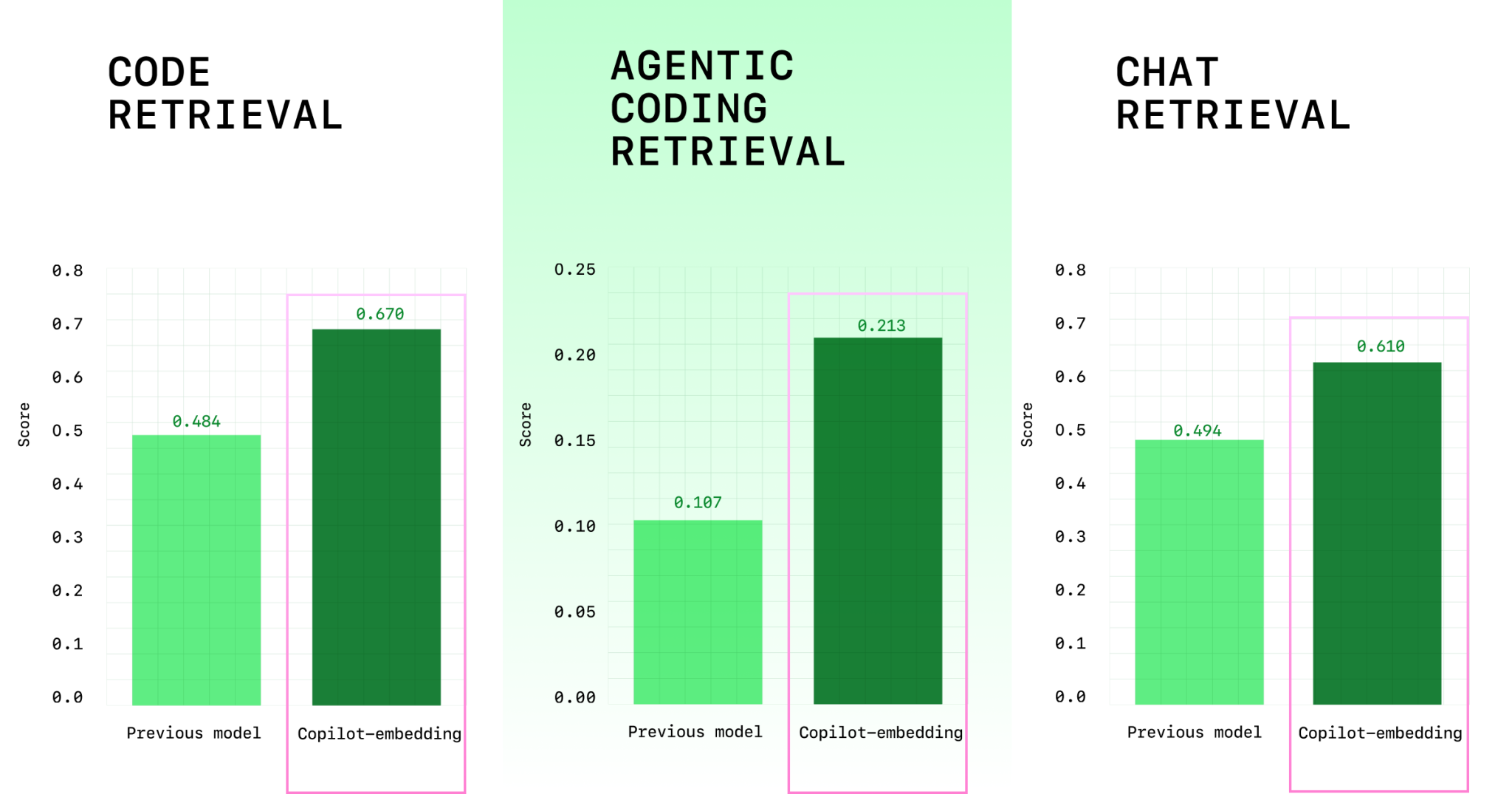
Crucially, the throughput was successfully doubled, leading to significantly lower latency for the end user. For an interactive tool like Copilot, speed is often as important as accuracy, and this improvement ensures a fluid developer experience. The memory optimization is equally critical; the memory usage dropped eightfold, making the index much more manageable and cheaper to maintain at scale. In head-to-head production testing, this new embedding model has consistently outperformed leading open-source and competitive models like VoyageCode3, Nomic Embed Code, and Jina Code Embeddings. The system is specifically suited to practical, real-world developer workloads, emphasizing robust performance over highly specialized, narrow benchmark success.
Developer Experience: Workflow and Productivity
The technical upgrades fundamentally translate into a smoother, more intelligent developer experience. Most notably, Copilot’s code search is now significantly more precise. When a developer asks Copilot for assistance or clarification, the underlying retrieval mechanism ensures the context is spot-on.
This precision results in a faster location of relevant functions, tests, and documentation across sprawling, multi-project repositories. Instead of manually jumping between files, Copilot can accurately pull in the necessary context, leading to better context-aware completions within the primary code-editing and review workflows. The benefits are a measurable reduction in irrelevant suggestions and a powerful improvement in recall (the model’s ability to find all relevant pieces of information). Ultimately, the core value proposition is clear: by significantly reducing the need for manual file and context switching, this model directly contributes to a tangible boost in developer productivity.
Integration and Ecosystem
The initial rollout is a native feature within VS Code, providing the tightest possible integration for speed and stability. However, GitHub has a clear roadmap for broader reach, with the rollout for the CLI and other major IDEs on the horizon.
The embedding-powered upgrades are the engine behind the enhanced capabilities of Copilot’s Chat, Agent, Edit, and Ask modes. It’s this foundational layer that allows these tools to be truly context-aware. A key technical enabler for large-scale adoption is the compressed index handling, which makes the model practical even for users working with truly massive repositories. Furthermore, the engineering has prioritized efficiency, ensuring the system remains responsive even on resource-constrained hardware. Looking ahead, the planned expansion for more languages and a broader ecosystem promises to make this powerful semantic search a universal standard across the Copilot suite.
The Future of Context-aware Assistance
The introduction of this advanced embedding model is more than just an iteration; it enables truly semantic and contextual reasoning within Copilot. By accurately mapping the latent semantic space of the codebase, Copilot can now reason about the relationships between different code entities, not just their literal text.
In practice, this means Copilot uses these embeddings to intelligently link code snippets, files, APIs, and documentation, creating a coherent, global understanding of the project. This deep, interconnected knowledge is the foundation for future innovations. The official roadmap includes support for more esoteric languages, the ability to perform cross-repository embeddings for mega-projects, and continual improvements to the model’s internal memory and context window management, positioning Copilot as a truly agentic coding partner.
FAQs and Developer Feedback
Initial community feedback has been overwhelmingly positive regarding the core performance gains. Developers are already reporting tangible retrieval and accuracy improvements in their daily workflows, particularly in large C# and Java applications. The primary area of demand, naturally, is for the CLI and JetBrains IDE rollout, which will bring the full power of the new model to a broader developer base.
Community feedback has become a critical input guiding the plans for language expansion and better coverage for existing less-represented languages. While the praise for the VS Code integration has been high, there have been some mixed reactions relating to existing limitations in certain non-core IDEs, highlighting the ongoing challenge of maintaining parity across all environments. The VS Code native experience, however, is consistently praised for its speed, accuracy, and interactivity.
Conclusion
The 2025 embedding model marks a critical leap in Copilot’s architecture and overall capability. By shifting from lexical to semantic matching, GitHub has delivered a system that is smarter, faster, and demonstrably more efficient at code retrieval and context assembly. This is an essential architectural upgrade.
These embedding-driven improvements fundamentally position Copilot for future agentic coding the ability for the AI to understand, plan, and execute multi-step coding tasks across a codebase. For developers and AI/ML engineers focused on retrieval-augmented generation (RAG) systems in the coding domain, this new model is the current state-of-the-art, promising a future where the AI helper is truly an intelligent, context-aware collaborator.
References & Further Reading
1] GitHub Blog: Copilot code search upgrade (2025)
Inspire Others – Share Now
Agentic AI Saksham
India’s Only 1st Ever Offline Hands-on program that adds 4 Global Certificates while making you a real engineer who has built their own AI Agents
EV
Saksham
India’s Only 1st Ever Offline Hands-on program that adds 4 Global Certificates while making you a real engineer who has built their own vehicle
Agentic AI LeadCamp
From AI User to AI Agent Builder — Capabl empowers non-coding professionals to ride the AI wave in just 4 days.
Agentic AI MasterCamp
A complete deployment ready program for Developers, Freelancers & Product Managers to be Agentic AI professionals

.png)
Table of Contents
1) Introduction
2) What’s New in the Copilot Embedding Model?
3) Under the Hood: Technical Improvements
4) Performance & Benchmark Results
5) Developer Experience: Workflow and Productivity
6) Integration and Ecosystem
7) The Future of Context-aware Assistance
8) FAQs and Developer Feedback
9) Conclusion
10 )References & Further Reading



