Why RAG? Addressing the Shortcomings of Traditional LLMs
LLMs like GPT-3 or LLaMA are massive transformer models trained on enormous datasets, encoding vast "parametric knowledge" in their parameters. They generate responses based on patterns from this training data when prompted. However, they face critical hurdles:
- Inaccessibility to Private Data: LLMs can't handle queries about proprietary or unseen data. For instance, they won't know details from a confidential company report or video without additional context.
- Knowledge Cutoff: Training ends at a specific date, so LLMs miss post-training events. Queries like "What's the latest on AI regulations in 2025?" fall flat unless the model has real-time access or updates.
- Hallucinations: LLMs can confidently output false information, like inventing historical facts, due to their probabilistic generation process.
Fine-tuning retraining on specialized data can mitigate these, but it's resource-intensive, requiring expertise, labeled data, and repeated efforts for updates. RAG offers a smarter, more agile alternative by fetching relevant data on-the-fly.
What is RAG?
Retrieval-Augmented Generation (RAG) combines two powerful ideas:
- Retrieval – pulling relevant information from external sources (like a database, documents, or transcripts).
- Generation – using a Large Language Model (LLM) to create responses.
Instead of relying only on what the LLM has memorized, RAG brings in fresh, reliable context at runtime no retraining needed. This uses in-context learning, where the model adapts based on examples or data it’s fed on the spot.
Think of it like this:
👉 You ask an LLM about a 3-hour lecture on machine learning. Instead of guessing from memory, RAG first retrieves the exact transcript segments (say, about neural networks), then passes them to the LLM. The result? Answers that are accurate, specific, and grounded in your actual source almost like having an expert teacher who flips to the right page before explaining.
Core Concepts You Need Before RAG
Before diving into the RAG pipeline, it’s important to understand the four fundamental building blocks that make RAG possible. These concepts form the foundation for indexing and retrieval:
- Document Loaders – How we bring external data (like PDFs, websites, or YouTube transcripts) into the system.
- Text Splitting – How large documents are broken into smaller, manageable chunks that fit within LLM context windows.
- Vector Stores – Where we store embeddings of the chunks, enabling fast and accurate similarity search.
- Retrievers – The interface that fetches the most relevant chunks from the vector store in response to a query.
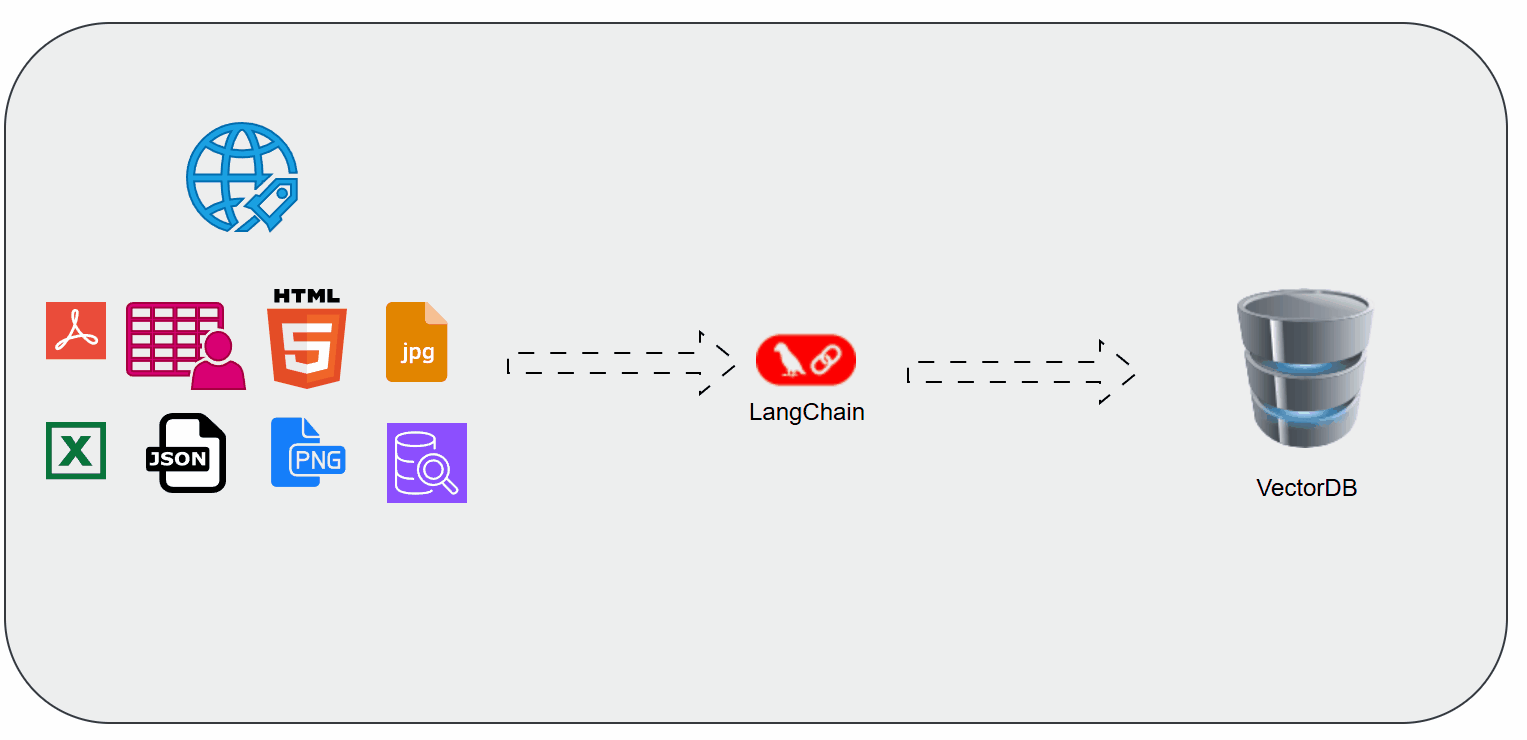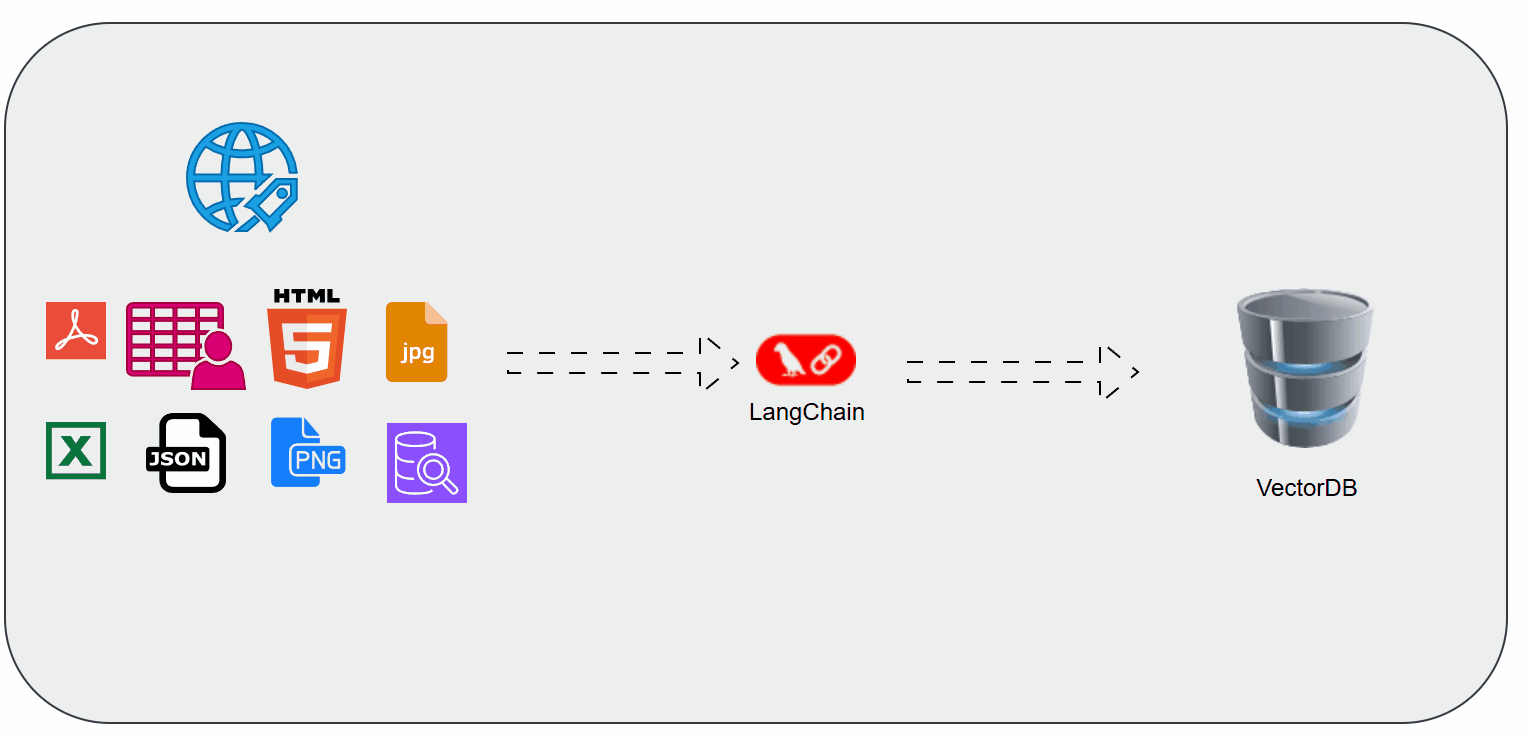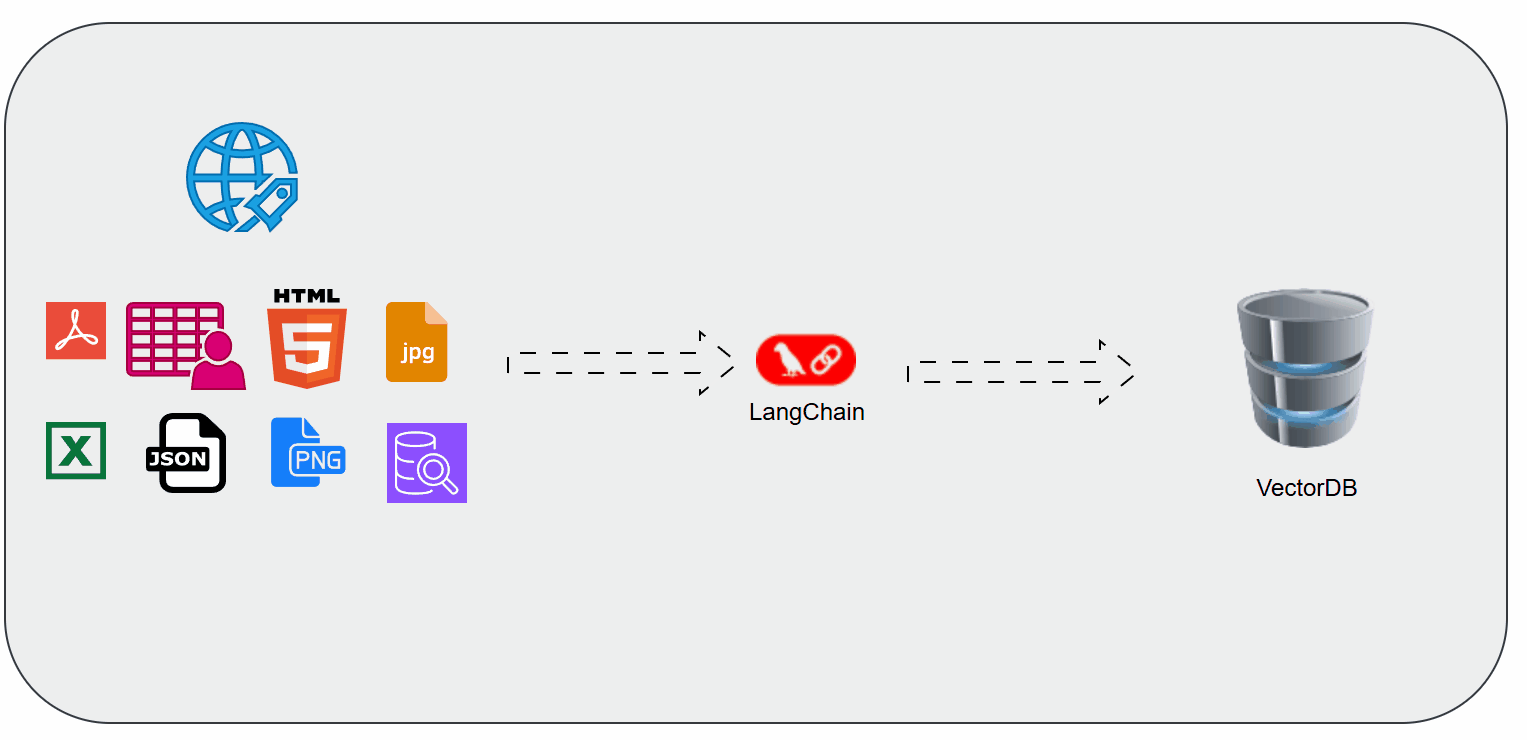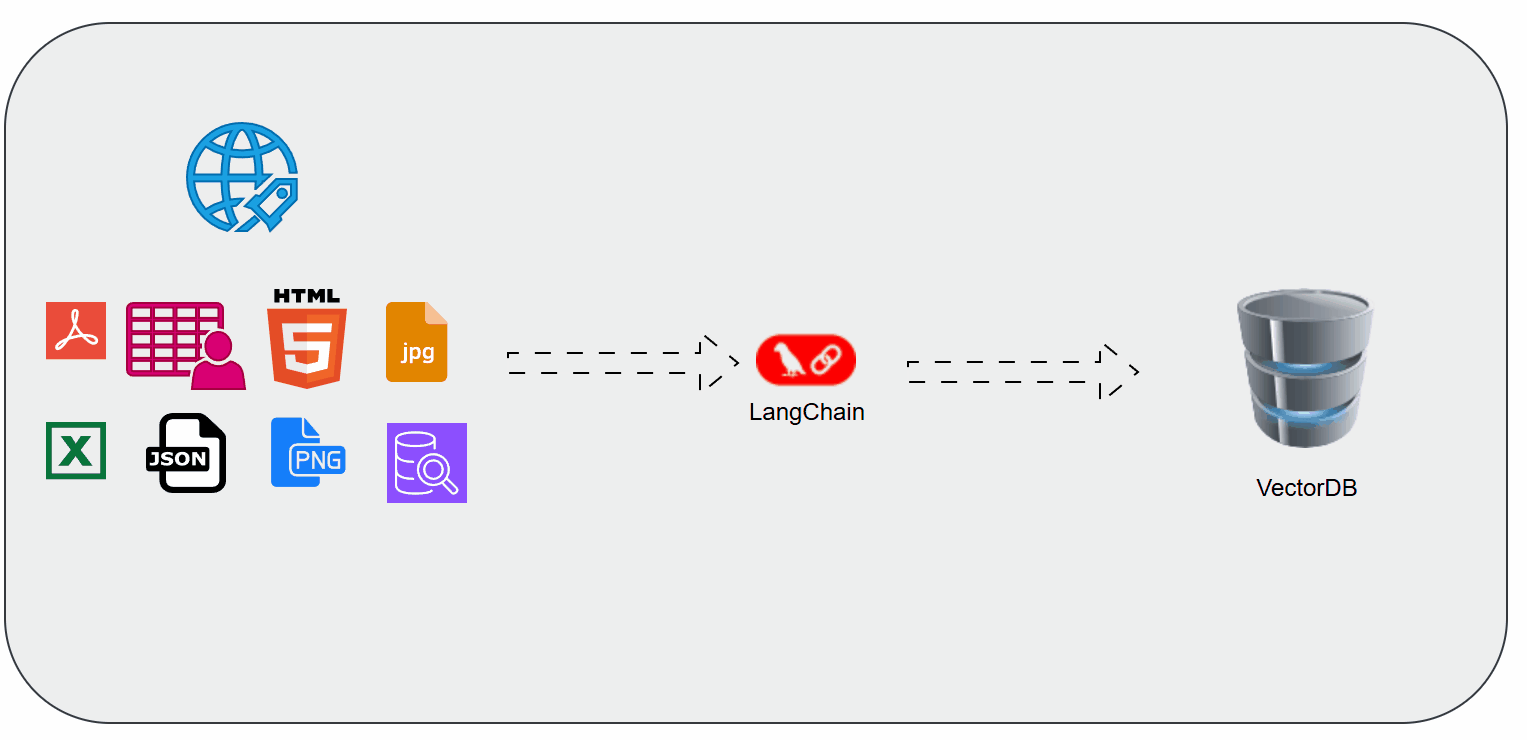
Document Loaders in LangChain
When working with Retrieval-Augmented Generation (RAG) or any AI application that uses external knowledge, the first step is getting your data into the pipeline. That’s where Document Loaders in LangChain come in.
They act as the bridge between raw data sources (PDFs, websites, Notion docs, databases, etc.) and the structured format that LLMs can understand.
Under document loader, we’ll cover:
- What Document Loaders are
- Why they’re important in RAG
- Types of document loaders in LangChain
- Example with updated LangChain v0.3+ syntax
- Best practices when loading documents
1. What are Document Loaders?
Document Loaders are utilities in LangChain that help you ingest data from different sources and represent them in a consistent structure (Document objects).
Each Document has two main components:
- Page Content → The actual text from the source.
- Metadata → Extra info like source name, page number, URL, etc.
This uniformity allows downstream steps like text splitting, embeddings, and retrieval to work seamlessly.
{ 2 } Text Splitting in LangChain: Smarter Chunking for Better AI
Large Language Models (LLMs) are powerful, but they come with a limitation: context window size. If you try to feed them a full book, PDF, or even a long blog post, you’ll quickly hit those limits.
This is why text splitting is one of the most important preprocessing steps when building Retrieval-Augmented Generation (RAG) pipelines, chatbots, or document question-answering systems. LangChain provides several strategies for splitting text into smaller, manageable chunks while still preserving meaning.
In this blog, we’ll explore the four main approaches to text splitting in LangChain, along with practical code examples.

{ 3 } Vector Stores : Mastering RAG Applications
Vector stores, a critical component of Retrieval-Augmented Generation (RAG) applications! This template explains what vector stores are, why they matter, and how to use them with LangChain, complete with a practical IPL player example. Perfect for developers and AI enthusiasts, this reusable template is designed for clarity and hands-on learning.
Why Vector Stores Matter
Understand the importance of vector stores through a real-world movie recommender system example.
Movie Catalog Scenario
- Objective: Build an IMDb-like website where users search for movies and view details.
- Setup:
- Database: Store movie data (ID, title, director, actors, genre, release date, hit/flop status) from APIs or web scraping.
- Backend & Frontend: Use Python to fetch and display data.
Adding a Recommender System
Enhance user engagement by suggesting similar movies (e.g., Iron Man for Spider-Man viewers) to increase time on site.
Initial Approach: Keyword Matching
- Method: Compare movies based on director, actors, genre, or release date.
- Flaws:
- Inaccurate Recommendations: My Name is Khan (drama about discrimination) might be paired with Kabhi Alvida Na Kehna (romantic drama) due to shared director/actor, despite different plots.
- Missed Similarities: Thematically similar movies like Taare Zameen Par and A Beautiful Mind are overlooked due to no common keywords
Better Approach: Semantic Plot Comparison
- Solution: Compare movie plots for thematic similarity.
- Implementation: Extract plot summaries (2,000–3,000 words) via APIs or scraping.
- Challenge: Semantic text comparison is complex, solved by embeddings.
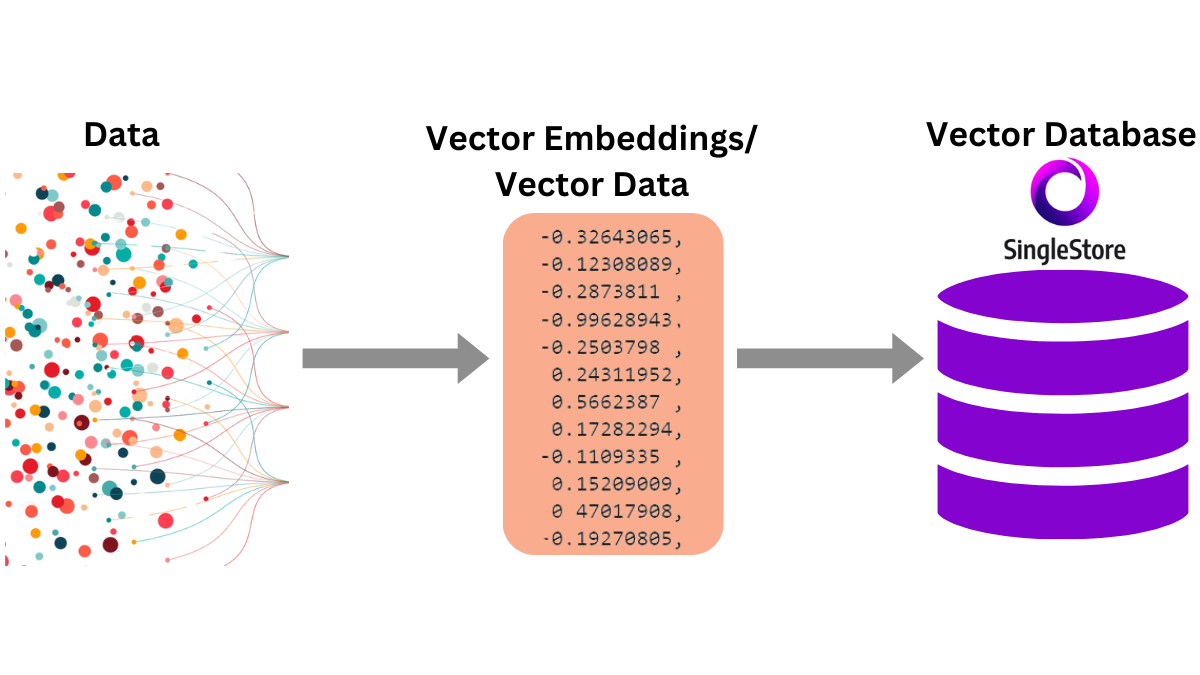
How Embeddings Work
- Definition: Convert text (e.g., plots) into numerical vectors (e.g., 512 dimensions) capturing semantic meaning using neural networks.
- Process:
- Feed text into a model (e.g., OpenAI embeddings).
- Output vectors and plot them in high-dimensional space.
- Measure similarity using cosine similarity (smaller distance = higher similarity).
- Example: For Stree, identify 3 Idiots as similar if their plot vectors align.
{ 4 } Understanding Retrievers in LangChain: A Key Component for RAG Applications
Retrievers are a cornerstone of Retrieval-Augmented Generation (RAG) applications in LangChain, enabling efficient fetching of relevant documents based on user queries. This blog dives into what retrievers are, why they’re essential, their different types, and how to implement them with practical code examples. Whether you're building a simple RAG system or an advanced one, understanding retrievers is crucial for creating intelligent, context-aware applications. This guide is designed for beginners and developers alike, offering a clear path to mastering retrievers in LangChain.
Why Retrievers Matter in RAG Systems
RAG applications combine retrieval and generation to deliver precise answers by fetching relevant documents and feeding them to a language model. Retrievers are the component responsible for the retrieval step, making them vital for RAG’s success.
The Role of Retrievers
- Definition: A retriever in LangChain is a component that fetches relevant documents from a data source in response to a user’s query.
- Functionality: It acts like a search engine, taking a query as input and returning a list of relevant
Documentobjects as output. - Data Sources: Retrievers can work with various data sources, such as vector stores, APIs, or external databases like Wikipedia.
- Flexibility: Retrievers are “runnables” in LangChain, meaning they can be integrated into chains or pipelines, enhancing system modularity.
Key Insight: Retrievers bridge the gap between user queries and relevant data, ensuring the language model receives the right context for accurate responses.
RAG Context
We’ve covered core RAG components:
- Document Loaders: Load data from various sources.
- Text Splitters: Break documents into manageable chunks.
- Vector Stores: Store embeddings for semantic search (covered in the previous blog).
- Retrievers: Fetch relevant documents (below).
With retrievers understood, you’ll be ready to build RAG applications in the next phase.
What Are Retrievers?
A retriever is a function that takes a user query as input, searches a data source, and returns relevant documents. It’s like a search engine tailored for specific data sources and search strategies.
How Retrievers Work
- Input: A user query (e.g., “What is photosynthesis?”).
- Processing: The retriever scans the data source (e.g., vector store, API) to identify relevant documents using a search strategy (e.g., semantic similarity).
- Output: A list of
Documentobjects, each containingpage_contentandmetadata.
Visual Analogy: Think of a retriever as a librarian who takes your question, searches the library (data source), and hands you the most relevant books (documents).
Key Characteristics
- Multiple Types: Retrievers vary based on data sources (e.g., Wikipedia, vector stores) or search strategies (e.g., similarity search, MMR).
- Runnables: As runnables, retrievers can be chained with other LangChain components (e.g., prompts, models) for seamless integration.
- Customization: Different retrievers address specific challenges, like redundancy or ambiguous queries.
Types of Retrievers
Retrievers can be categorized based on two criteria:
- Data Source: The type of data they fetch from (e.g., Wikipedia, vector stores).
- Search Strategy: The mechanism used to identify relevant documents (e.g., similarity search, MMR, multi-query).
The RAG Pipeline: A Step-by-Step Breakdown
RAG follows a structured flow: Indexing, Retrieval, Augmentation, and Generation. We'll illustrate with an example of a chatbot for educational videos.
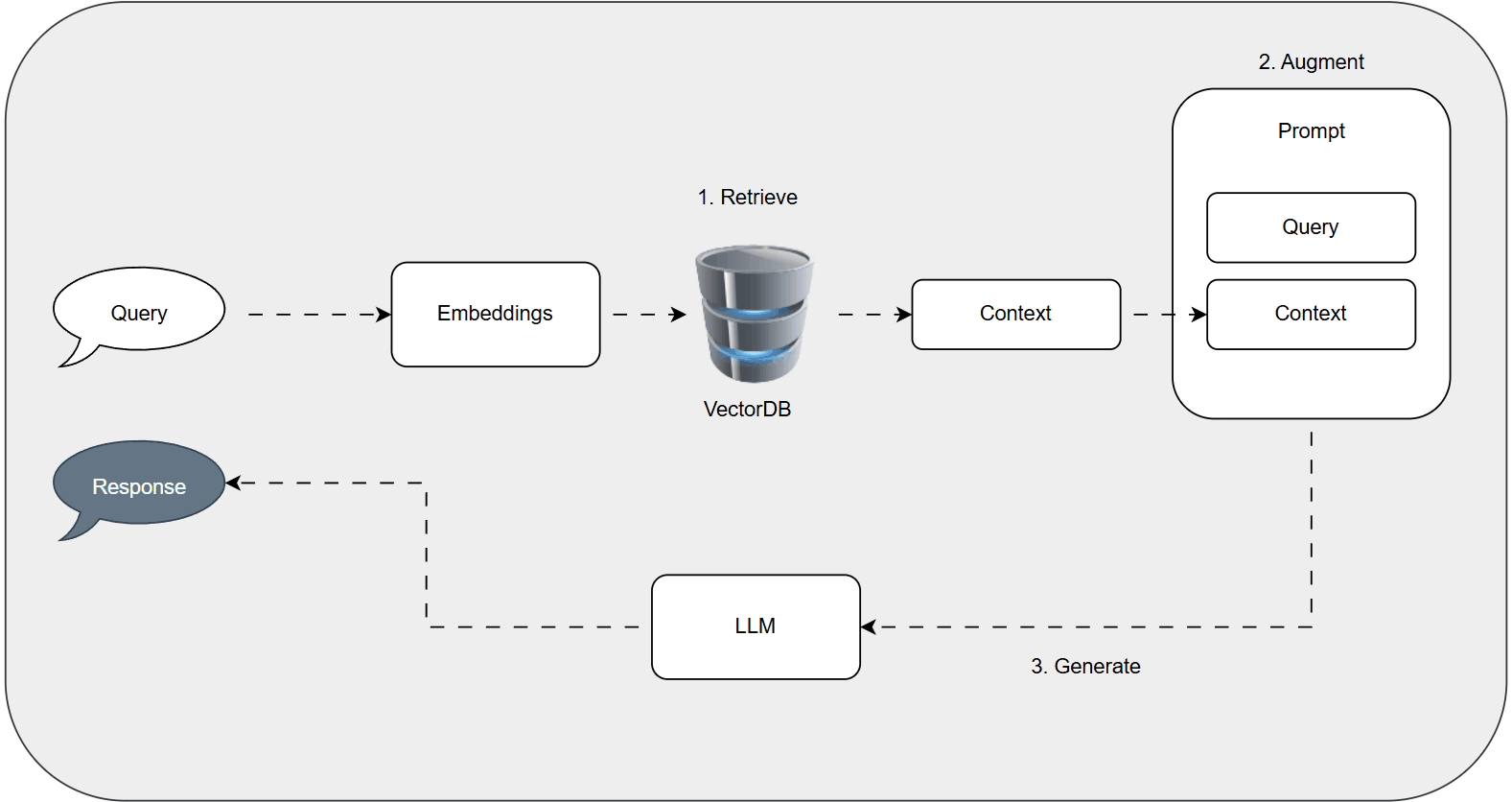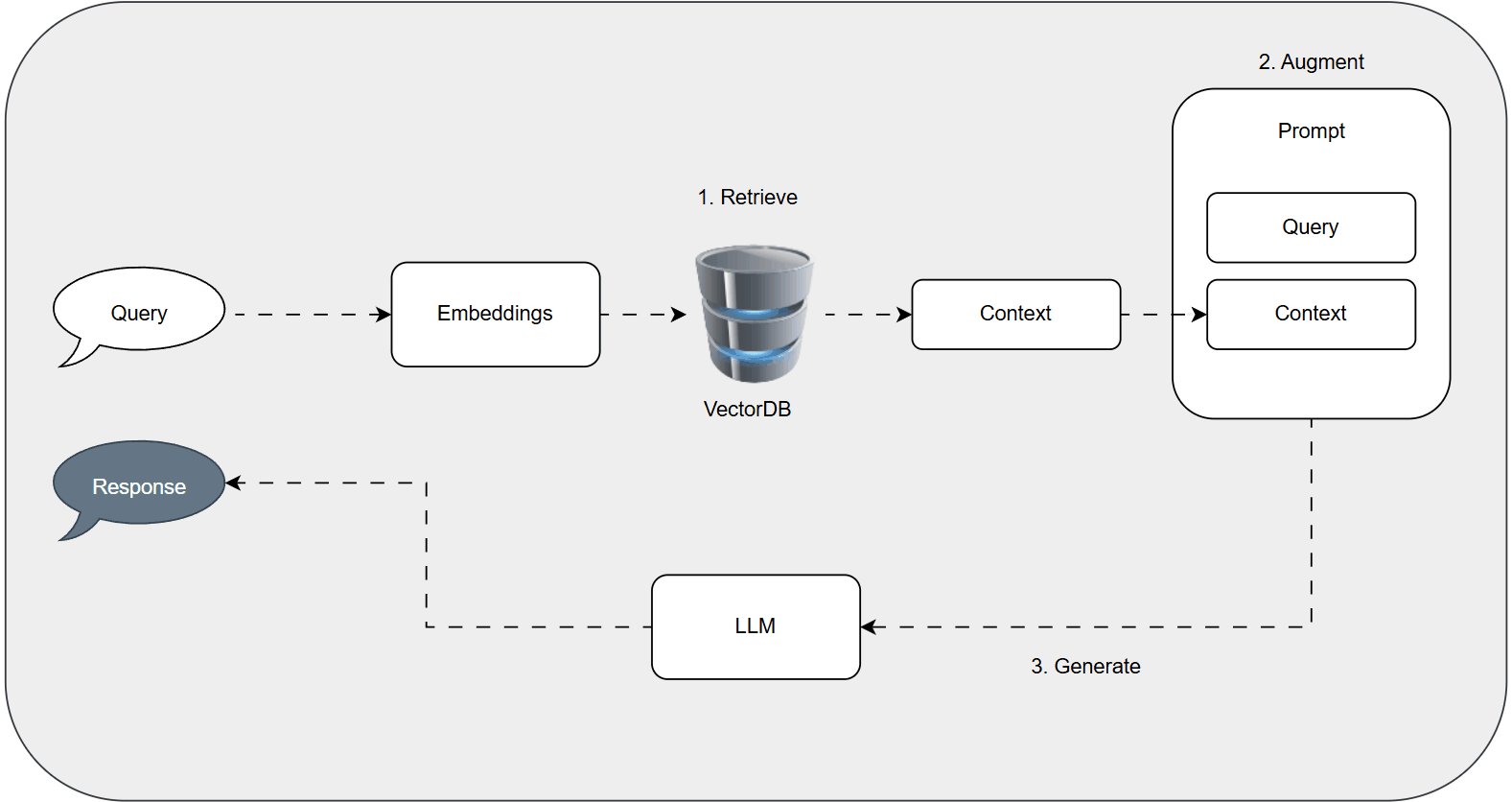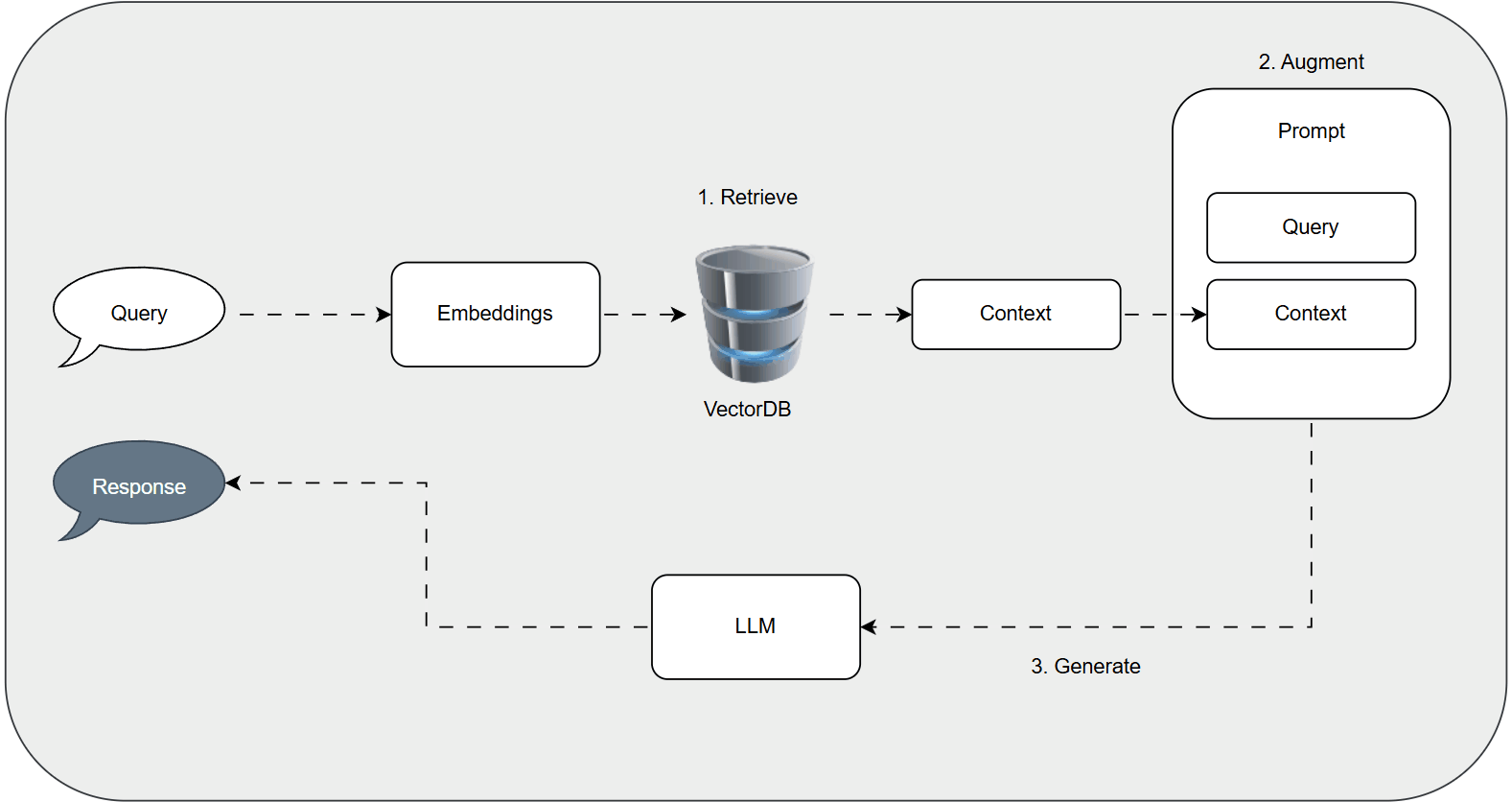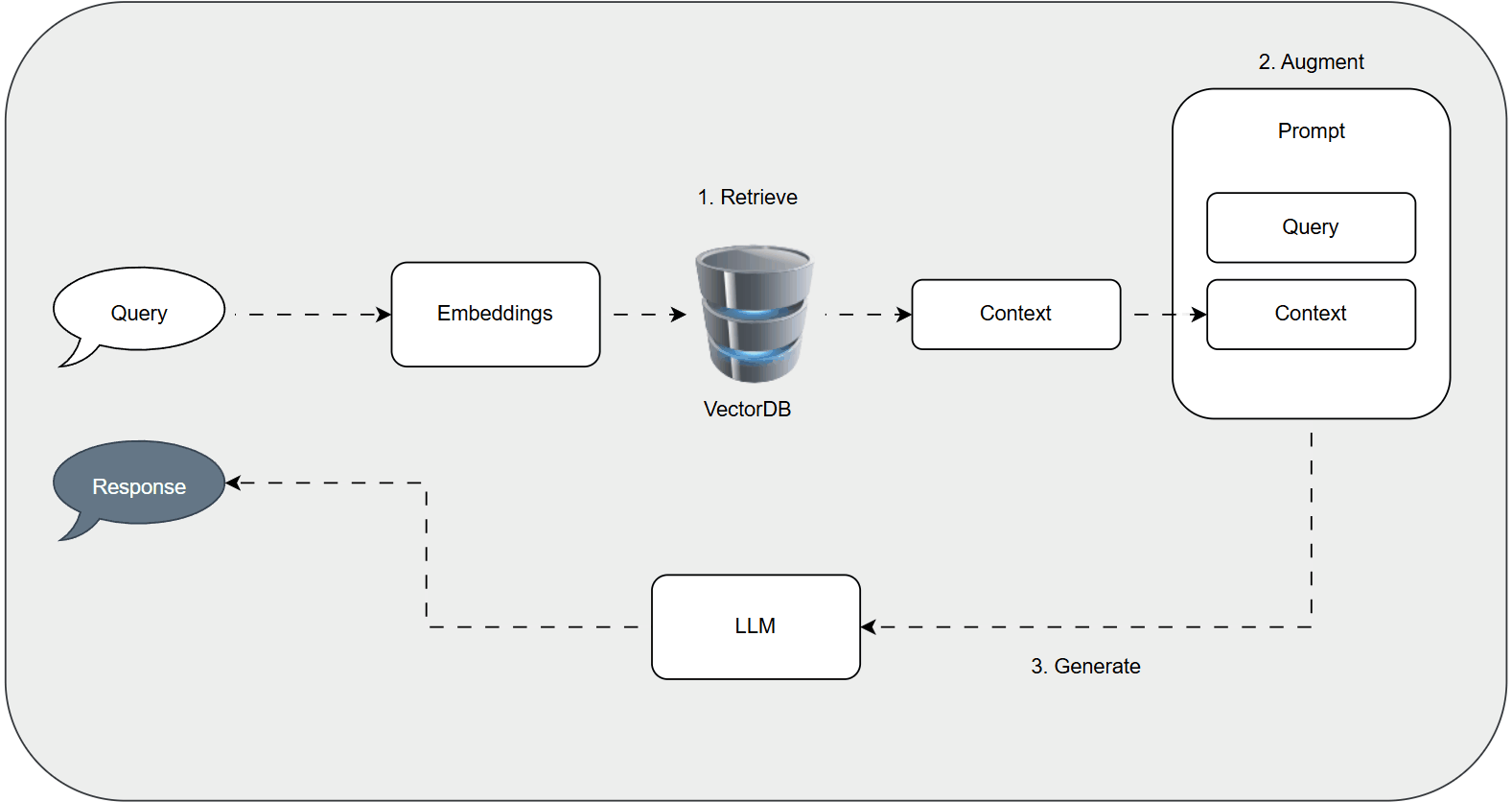
1. Indexing: Preparing the Knowledge Base
This stage creates a searchable repository:
- Document Ingestion: Load data, such as video transcripts or documents, using tools like LangChain's loaders (e.g., YouTubeLoader for transcripts).
- Text Chunking: Split content into manageable pieces with overlap for context preservation. LangChain's RecursiveCharacterTextSplitter handles this, keeping chunks under token limits.
- Embedding Generation: Transform chunks into vector embeddings using models like OpenAI's text-embedding-3-small for semantic representation.
- Vector Storage: Save embeddings and metadata in a vector database like FAISS for fast similarity searches.
2. Retrieval: Matching Queries to Context
For a query like "Explain gradient descent optimization":
- Embed the query.
- Search the vector store for similar embeddings (e.g., via cosine similarity).
- Retrieve and rank top chunks, extracting relevant text (e.g., video segments on the topic).
3. Augmentation: Building the Enhanced Prompt
Combine the query and retrieved context:
You are a helpful assistant. Answer the question only from the provided context. If the context is insufficient, say "I don’t know" to avoid hallucination.
**Context**: [Relevant transcript chunks]
**Question**: [User query]This grounds the LLM in factual data.
4. Generation: Crafting the Response
Feed the prompt to an LLM (e.g., GPT-4o-mini), which synthesizes a response using both its knowledge and the context, reducing errors.
Master the Full RAG Pipeline: Build Reliable, Context-Aware AI
You've successfully demystified the "Why" and "How" of RAG, moving past the limitations of traditional LLMs that suffer from hallucinations and knowledge cutoffs. You now understand the four core building blocks: Document Loaders, Text Splitting, Vector Stores, and Retrievers.
This theoretical knowledge is powerful, but building production-ready AI requires translating concepts into code.
The AI Agent Mastercamp by Capabl is a fully hands-on program where you won't just learn about the RAG pipeline you will build it from end to end.
You will gain practical mastery over:
- Ingestion: Building robust Document Loaders and implementing advanced Text Splitting strategies to handle complex proprietary data.
- Vectorization & Storage: Setting up and optimizing Vector Stores for lightning-fast semantic retrieval and long term memory.
- Agentic Integration: Combining RAG with the ReAct Framework to create autonomous AI Agents that are accurate, contextual, and grounded in fact.
Stop just knowing about RAG and start building RAG powered Agents.
Enroll in the Agentic AI Mastercamp or Agentic AI LeadCamp today and become the architect of reliable, context-aware AI solutions.
Conclusion
Retrieval-Augmented Generation is more than just a workaround it’s a game-changer in how we build AI applications. By combining the generative power of LLMs with dynamic retrieval, RAG makes models more reliable, adaptable, and grounded in real-world data, solving challenges like hallucinations, outdated knowledge, and limited access to private information.
The future of AI isn’t just about bigger models it’s about smarter systems that can reason with the right information at the right time. Start experimenting, share your creations, and be part of shaping that future.
Inspire Others – Share Now
Agentic AI Saksham
India’s Only 1st Ever Offline Hands-on program that adds 4 Global Certificates while making you a real engineer who has built their own AI Agents
EV
Saksham
India’s Only 1st Ever Offline Hands-on program that adds 4 Global Certificates while making you a real engineer who has built their own vehicle
Agentic AI LeadCamp
From AI User to AI Agent Builder — Capabl empowers non-coding professionals to ride the AI wave in just 4 days.
Agentic AI MasterCamp
A complete deployment ready program for Developers, Freelancers & Product Managers to be Agentic AI professionals

.png)