We've seen Large Language Models (LLMs) like GPT and Gemini evolve from fascinating toys to powerful tools that have totally changed how we work and create. But honestly, even these giants have a major, almost philosophical, limitation: they are essentially frozen in time. Once their training finishes, their knowledge and reasoning are static. They can look up new information using tools, sure, but they can't internalize it. They don't actually learn and update their core understanding on the fly.
This is exactly why adaptivity matters in modern AI systems. The world moves fast. Facts change, user preferences shift, and novel tasks pop up all the time. An AI that can't learn continuously is an AI that's constantly falling behind. So, what’s the fix? MIT’s researchers have stepped in with a brilliant answer: the Self-Adapting Language Model (Self-Adapting LM) framework, which they call SEAL.
What is MIT’s Self-Adapting LM?
The core idea behind SEAL is simple yet revolutionary: give the LLM the power to teach itself.
A standard LLM is a phenomenal predictor but a passive learner once deployed. The goal of SEAL is to transition the model from a passive responder to an autonomous learner. The motivation is simple: if models are to become truly intelligent, agentic, and continually useful, they must be able to change their own internal logic and knowledge. This isn't just about feeding it a new document; it’s about allowing the model to restructure its own weights (the internal parameters that define its "knowledge") in response to a new experience.
How Self-Adapting LMs Work
How does a computer program learn how to edit itself? It’s all about creating an adaptive architecture powered by a real-time feedback loop.
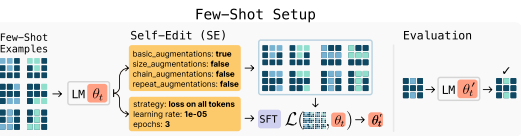
SEAL works by training the LLM to generate its own training data and update instructions, which they call "self-edits."
- Generate a Self-Edit: When the model encounters new information (like a fresh fact in a passage) or a challenging task, it generates a "self-edit." This self-edit is a natural language instruction that dictates an update, such as "Generate a set of logical implications from this text," or "Apply data augmentation by rotating the input image."
- Apply the Update: The model then uses this self-edit to perform a lightweight fine-tuning on its own weights using techniques like LoRA (Low-Rank Adaptation). This updates the model’s internal knowledge persistently.
- Evaluate and Reinforce: After the update, the system tests the model on a downstream task. Did the model get better? The performance on this task becomes the reward signal in a Reinforcement Learning (RL) loop.

The difference from static LLMs is monumental. Static LLMs only change with a massive, expensive, manual retraining cycle. SEAL is designed for lasting, continuous adaptation, the model changes its mind, and that change sticks, much like when a human student restructures their notes to better internalize a concept.
Key Innovations
The self-adapting nature of SEAL is built on a few stunning technical breakthroughs.
The most critical innovation is the concept of a modular self-optimization layer that is actually inside the model itself. Unlike approaches that bolt on external memory or a separate adapter network, SEAL uses the LLM's own generative capacity to parameterize and control its adaptation process. The model writes the script for its own learning.
This leads directly to automatic task adjustment. For a simple task, a light touch might be needed. For a complex reasoning puzzle, the model might automatically specify a more aggressive learning rate or more detailed data augmentations. The system learns to select the optimal learning strategy.
Finally, the reinforcement-based fine-tuning using the ReST EM algorithm is what makes the self-edits effective. The RL loop ensures that the model doesn't just generate any updates, but only those updates that demonstrably improve its performance on a target task. It’s smarter than just trial-and-error; it’s learning how to learn successfully.
The Science Behind Adaptivity
Under the hood, this framework leverages two powerful concepts: in-context learning and meta-learning.
In-context learning (ICL), which lets LLMs perform tasks based on examples provided in the prompt, gives the model the capability to generate the self-edits in the first place. The model is prompted to be a "self-editor" or a "self-teacher."
However, ICL's effect is temporary, it’s gone with the next prompt. Meta-learning is what provides the permanence. By using RL, the model is learning a higher-level skill: how to map a new input into an effective weight update. It’s not just solving the task; it’s learning the meta-skill of adaptation. This dynamic model behavior is what transforms it from a sophisticated lookup table into a truly adaptive intelligence.
Applications and Use Cases
The real world is messy, and that's where SEAL shines. This capability to self-modify has huge implications:
- Personalized Assistants: Imagine an AI assistant that truly absorbs your unique writing style, obscure personal facts, and specific workflow preferences after just a few interactions. It becomes a bespoke AI just for you.
- Autonomous Systems: For AI agents engaged in long-running or mission-critical tasks, like robotics or financial trading, the ability to coordinate in multi-agent systems and update shared knowledge without downtime is a game-changer.
- Real-Time Knowledge Bases: Forget the problem of "knowledge cutoffs." A self-adapting model could ingest the latest news, regulations, or product specs and update its knowledge base instantly.
Performance and Evaluation
When the MIT team evaluated SEAL, the results were quite compelling, especially when compared to just standard fine-tuning or in-context learning.
In tasks like Knowledge Incorporation (teaching the model a new fact and testing if it remembers it without the source text), a smaller model using SEAL actually outperformed fine-tuning on synthetic data generated by models like GPT-4. On few-shot abstract reasoning tasks, SEAL achieved massive performance gains, showcasing its ability to truly generalize from a minimal number of examples.
The metric here isn't just standard accuracy, but adaptivity metrics, how quickly and effectively the model can change its parameters to improve its score on a novel task. The scalability is also exciting: because the updates are focused (using LoRA) and self-generated, it points a way toward more efficient continuous learning systems that don't need a supercomputer for every update cycle.
Challenges and Limitations
Of course, the road to AGI is never perfectly smooth. SEAL faces real obstacles.
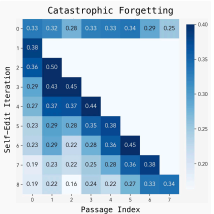
The biggest technical challenge is catastrophic forgetting. When the model updates its weights to learn something new, it might accidentally overwrite or forget valuable, older information. Addressing this issue, a classic problem in continual learning, is essential for a stable system.
There's also the computation cost. Every "self-edit" requires a full fine-tuning and evaluation cycle, which can be computationally expensive and time-consuming, even with lightweight methods. We need faster ways for the model to "try out" an update.
Finally, the ethical or security concerns are amplified. If an AI can reprogram itself based on new, uncurated input, that introduces a new vector for data poisoning, bias reinforcement, or unpredicted behavior drift. Robust guardrails for self-modification will be absolutely necessary.
Future Directions
I believe SEAL is a critical stepping stone toward the next generation of AI: self-evolving and truly agentic AI systems.
If a model can learn how to learn, the next step is to teach it when to learn. Imagine an agent that reasons about its own uncertainty mid-task and decides, "I'm unsure about this fact; I should generate a self-edit to internalize the correct information." This iterative, self-reflective improvement could distill ephemeral chain-of-thought traces into permanent knowledge, creating models that continuously grow their capabilities through interaction and reflection. This is the definition of a truly agentic AI.
Conclusion
The concept of adaptive intelligence is not just shaping the future of AI; it is the future of AI. MIT’s Self-Adapting LM framework, SEAL, represents a profound shift away from the static, batch-trained models of yesterday toward dynamic, self-improving systems. By giving LLMs the keys to their own cognitive architecture, we are unfreezing the genius within and paving the way for AI assistants, agents, and autonomous systems that will be perpetually up-to-date, hyper-personalized, and, most importantly, continuously getting smarter.
Inspire Others – Share Now
Agentic AI Saksham
India’s Only 1st Ever Offline Hands-on program that adds 4 Global Certificates while making you a real engineer who has built their own AI Agents
EV
Saksham
India’s Only 1st Ever Offline Hands-on program that adds 4 Global Certificates while making you a real engineer who has built their own vehicle
Agentic AI LeadCamp
From AI User to AI Agent Builder — Capabl empowers non-coding professionals to ride the AI wave in just 4 days.
Agentic AI MasterCamp
A complete deployment ready program for Developers, Freelancers & Product Managers to be Agentic AI professionals

.png)